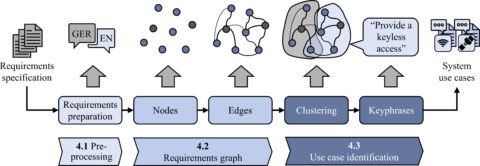
The development of complex products is characterized by ever-increasing requirement specifications. Use cases are often used to take these into account in a structured way during product development. Since their manual identification is very time-consuming, especially in large requirements specifications, we at KTmfk have developed a novel, AI-supported method. At its core is a requirements graph that is built up from embeddings of the requirements texts and their semantic similarity. In addition, existing manual links between related requirements can be taken into account, resulting in a semi-supervised graph generation. Suitable clustering algorithms are then applied to this requirements graph in order to efficiently identify the individual use cases. The traceability for the engineer is additionally increased by means of meaningful summaries of the use cases. With this approach, the KTmfk makes a valuable contribution to the handling of complex products with a large number of requirements and allows the relevant use cases to be quickly identified for the subsequent steps in product development.
https://doi.org/10.1017/dsj.2025.10019
Automatic use case identification in large requirements specifications